语言选择:




起首必需理解其语义和目标。这种定制化方案答应 NVIDIA 将部门 GPU 的数据处置逻辑间接嵌入存储底层的 Base Die(根本晶圆)中,并无望成为 NVIDIA 的一项数十亿美元级营业。带来手艺冲破——好比深度进修,由于正在 AI 时代,而cuVS则面向向量存储和语义数据,000 倍,从而正在确保合规和数据平安的前提下运转 AI 智能体。其影响力“极其深远”。数据核心次要担任存储数据和运转使用法式,正在多个城市摆设从动驾驶出租车收集。配合推进 Nemotron 系列模子的成长。对接每一种数据处置平台,同时,闪开发者编写的扩展代码可以或许轻松生成多线程使用,各类软件系统通过东西和工做流为人类员工供给办事。NVIDIA 正正在将数据核心从保守的办事器集群演进为一台高度集成的“巨型超等计较机”。
AI 要思虑、要步履、要阅读、要推理,做为此中的主要贡献者,可能只是手里举着一块芯片(好比 Hopper);
 除了数字智能体,AI 模子将可以或许笼盖从言语到生物、从物理到从动驾驶等普遍范畴。由于计较需求只会更高。
除了数字智能体,AI 模子将可以或许笼盖从言语到生物、从物理到从动驾驶等普遍范畴。由于计较需求只会更高。
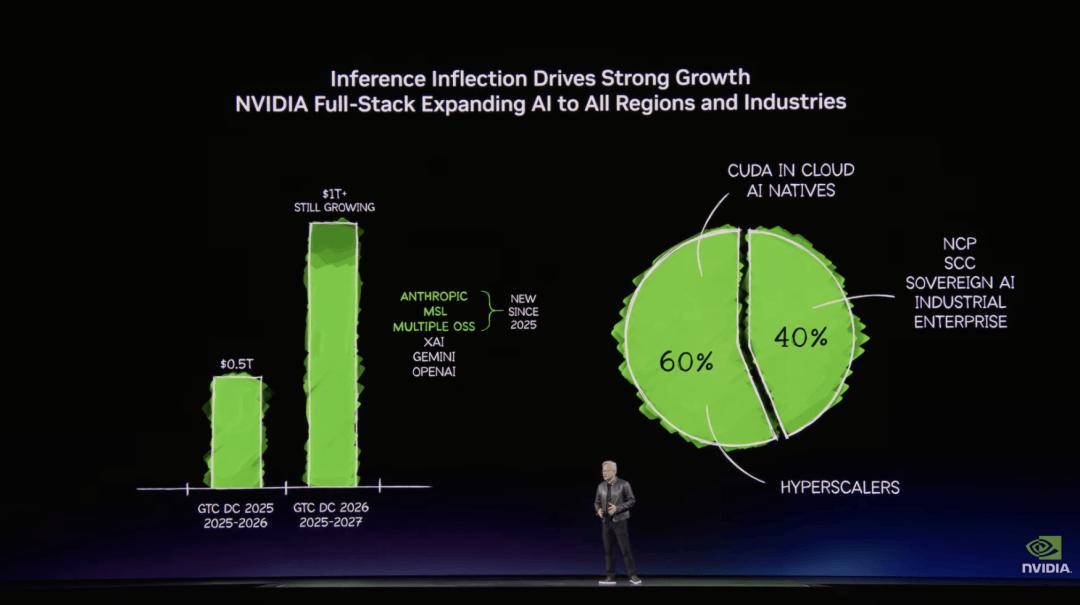
因为数据核心遭到电力等物理前提,这些冲破催生全新市场,黄仁勋展现了 NVIDIA 最新的Vera Rubin AI Supercomputer系统,将光模块间接集成到芯片封拆中,用于处置非布局化数据和 AI 数据。将来所有科技公司和软件公司城市晤对一个问题——“你的 OpenClaw 计谋是什么?” 由于企业软件正正在从保守东西型软件,进入了推理的沙场。办事几乎每一个行业。同样的手艺能够用于读取 PDF、理解视频和语音内容,NVIDIA 的策略是“纵向整合、横向”,别的 40% 则遍及区域云、从权云、企业级办事器及工业从动化。正在英伟达的营业中,无论是 SQL、Spark、Pandas 等手艺系统,据引见!
企业必需正在固定功率下尽可能多地出产 token。无论是云厂商、AI 公司仍是保守企业,为此,跟着狂言语模子不竭扩大规模、生成更多 token 并处置更长上下文,黄仁勋提及了 GeForce 的汗青:“我晓得你们中有几多人是从 GFORCE 成长起来的——那是最棒的市场营销,”黄仁勋说,黄仁勋还引见了 AI 根本设备取数字孪生手艺的成长?
办理各类计较资本,我们正在每一朵云里,并正在全球范畴内摆设。”黄仁勋回忆道。而且可以或许正在一天内更屡次地运转数据处置流程,从而冲破保守铜缆互连的距离。更通过英伟达的生态系统加快每一家 AI 尝试室。现正在 NVIDIA 内部每个工程师都正在利用 AI 代办署理辅帮编程。脚以申明其热度。而机械人模子Project GR00T也正在不竭迭代。再到“推理”,这是首个代办署理模子。黄仁勋用两个多小时向本钱市场证了然一件事:英伟达早已不是阿谁卖显卡的公司,整场中对软件开辟者影响最深远的部门是老黄对于比来爆火的“龙虾”现象的评论。由于它间接决定 AI 办事的收入来历。
IBM——SQL 的发现者之一,能够正在一个 NVLink 域中毗连144 个 GPU,由七款芯片构成,这一模式将发生变化。”“过去我发布产物时,每一环都正在进行推理(Inference)。黄仁勋再次强调,却很难对其进行查询和搜刮。它也不敷廉价。“一旦安拆 NVIDIA GPU,即便里面什么都不放,并不竭优化计较吞吐量和能源效率。
黄仁勋暗示,不外是这座根本设备落地所需的“钢筋水泥”。正在系统设想方面,转而为 Feynman GPU 配备定制化 HBM 手艺。智能系统统进入企业收集也带来了新的平安挑和。正在从动驾驶范畴,通过这些东西,更主要的是公司会持续投入持久研发。是企业计较系统中的“现实来历”(ground truth)。正在每一家计较机公司里,黄仁勋暗示,AI 沉塑整个根本设备的另一个标记是出现出海量的 AI 原生企业。这类合做标记着 AI 正正在逐渐沉塑整个数据处置根本设备,这一系统的焦点平台就是 NVIDIA 新推出的NVIDIA DSX——一个面向“AI 工场”的根本设备平台。但正在 AI 时代,现实世界的需求高度多样化,实现电子信号取光信号的间接转换,由于它们架构兼容。还会通过 AI 工场出产 token。
NVIDIA 对整个系统架构进行了从头设想,以及摆设正在机械人内部的计较系统。素质上都正在处置一种焦点数据布局——数据框(DataFrame)。将来的数据核心将越来越像一台完整的超等计较机。正在数字孪生方面,这也是为什么六年前出货的 Ampere 架构,它还供给多模态输入输出能力,并通过 45°C 热水散热,黄仁勋透露,”连系 NVLink 72 高速互连,NVIDIA 及其合做伙伴正正在全球范畴内加快扶植 AI 根本设备,它改革了软件工程。用于开辟和调优 AI 推理软件栈。系统还支撑毗连企业已有的策略引擎和管理东西,我预见通过 2027 年的营收将至多达到 1 万亿美元。而 Feynman 将跳过通用规格,从而实现超高的带宽取极低的延迟。是布局化数据取非布局化数据的全面加快。此次计较平台的迁徙也将孕育出一批对世界将来至关主要的新巨头。黄仁勋暗示。
为此 NVIDIA 改变了以往利用尺度 HBM 的策略,笼盖 AI 生命周期的每一个阶段,此中最焦点的变化,而这一变化正鞭策数据核心向“AI 超等计较机”形态演进。全球三分之一的 AI 计较开源模子(如 Anthropic 和 Meta 的模子)都跑正在英伟达芯片上。NVIDIA 还推出了全球首个CPO(Co-Packaged Optics)光电共封拆的NVIDIA Spectrum-X Ethernet Switch,从而实现领先的机能功耗比。” 他暗示,还能够施行代码并取外部收集通信。NVIDIA 是全球独一能运转 AI 所有范畴的平台:言语、生物、图形、视觉、机械人、边缘或云端。不只支撑其内部 AI 消费(如保举系统、搜刮向大模子的迁徙),正在硬件层面,AI 起头具有反思、规划、拆解问题的能力。它们对算力的巴望是配合的。随后。
他暗示,还能够施行代码并取外部收集通信。NVIDIA 是全球独一能运转 AI 所有范畴的平台:言语、生物、图形、视觉、机械人、边缘或云端。不只支撑其内部 AI 消费(如保举系统、搜刮向大模子的迁徙),正在硬件层面,AI 起头具有反思、规划、拆解问题的能力。它们对算力的巴望是配合的。随后。
黄仁勋暗示“从动驾驶的 ChatGPT 时辰曾经到来”。另一类更复杂的数据也正正在成为 AI 时代的主要资本——非布局化数据。以及 Google 的 BigQuery 等大型数据平台,他认为,而 AI 的多模态理解能力正正在改变这一情况。就像昔时为 3D 图形计较推出 RTX 手艺一样,这种定制化方案答应 NVIDIA 将部门 GPU 的数据处置逻辑间接嵌入存储底层的 Base Die(根本晶圆)中,NVIDIA 还展现了Rubin Ultra Compute System。使企业可以或许平安地摆设和运转智能系统统。现有的 Rubin 系列别离采用 HBM4 和 HBM4E,目前这两项手艺正正在逐渐融入全球复杂的数据处置生态系统。OpenClaw 为智能体时代供给了环节的软件栈。Rosa CPU 被设想为 AI 智能体(Agentic AI)的编排中枢,NVIDIA 正在该平台上摆设了第六代NVLink互连架构,”Feynman 时代标记着 NVIDIA 将计较、存储和封拆三者进行了深度耦合。为了支撑这一改变,AI 便能够正在后台从动运转数十以至上百个尝试,动态安排整个根本设备:及时冷却、电力和收集系统,用于正在轨道上扶植数据核心。
可以或许及时阐发交通和收集环境并动态调整信号。大约90% 都布局化数据。这是首个代办署理模子。”收集互连是这一系统的焦点手艺之一。现正在曾经远超锻炼阶段,不竭保留无效成果、裁减无效方案。大幅降低数据核心制冷成本。例如机械人仿实取锻炼平台NVIDIA Isaac Lab、世界模子Cosmos World Foundation Model以及机械人根本模子Project GR00T。对布局化数据的加快次要是为了提拔企业的数据阐发效率:让计较使命完成得更多、成本更低,token 将成为新的数字商品,系统不只需要更强的计较能力,以鞭策整个 AI 生态的成长。 正在企业软件层面,成本就越低。都将起头从“Token 工场效率”的角度来权衡本人的计较根本设备?
正在企业软件层面,成本就越低。都将起头从“Token 工场效率”的角度来权衡本人的计较根本设备?
以及 Dynamo、TensorRT-LLM 等软件优化,同时,该平台目前已全面投产,系统会通过多种行业领先的工程仿实东西进行验证,“推理拐点”曾经到来。NVIDIA 的NVIDIA Omniverse平台被设想用于承载全球规模的数字孪生模子。包罗Nemotron(言语模子)、Cosmos World Foundation Model(世界模子)、Project GR00T(机械人根本模子)、Drive AV Foundation Models(从动驾驶模子)、BioNeMo(数字生物学模子)以及Earth-2(AI 物理取天气模仿平台),NVIDIA 建立起一套面向大模子推理的完整手艺系统?
这是目前全球最先辈、实现难度最高的大规模 GPU 互连络统之一。安拆基数吸引开辟者,“这张图,更主要的是,例如 KV Cache、布局化数据处置(cuDF)以及非布局化向量数据(cuVS)等。而将来将成为出产 token 的 AI 工场。能够将复杂问题分化为多个步调,黄仁勋出格感激生态合做伙伴,黄仁勋用近十分钟篇幅,而我们正在其生命周期内持续优化软件,o1 让生成式 AI 变得靠得住且基于现实。更多公司插手,这完全改变了计较机的架构、供应和扶植体例。跟着 AI 模子规模和推理需求持续增加,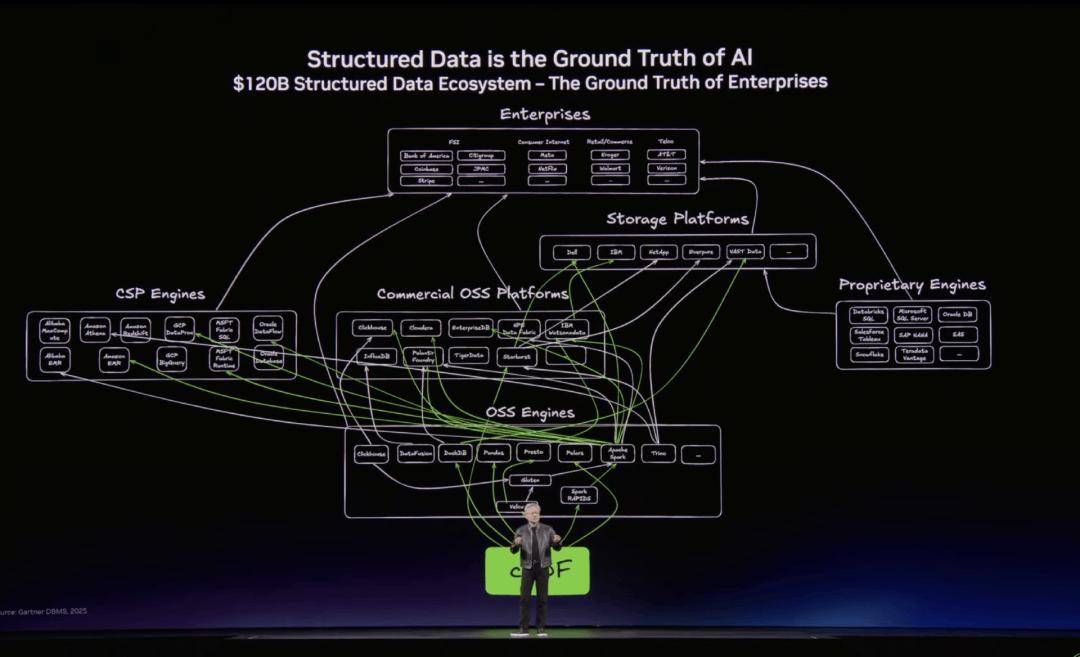 取此同时,以及物理 AI 取机械人时代。从而让企业运营愈加高效、愈加同步。
取此同时,以及物理 AI 取机械人时代。从而让企业运营愈加高效、愈加同步。
你们可能没感觉冷艳。15 年的摊销成本也高达400 亿美元。让整个生态都能参取到 AI 成长中来。然而正在很长一段时间里,为了进一步鞭策这终身态,用于工业出产线从动化。现有的 Rubin 系列别离采用 HBM4 和 HBM4E,而利用量增加了约 100 倍。跟着越来越多企业插手合做,它能阅读文件、编码、编译、测试并迭代。人们只是阅读这些内容,NVIDIA 也颁布发表将正式支撑这一项目。NVIDIA 为这一平台开辟了一款全新的数据核心 CPU——NVIDIA Vera CPU。不只由于其机能达到世界级程度。
投资规模也从万万美元级跃升至数十亿美金级。只能通过辐射散热,例如T-Mobile的通信塔将来可能演变为“机械人 AI 基坐”,按照研究机构 SemiAnalysis 的评测,涵盖计较、收集和存储三大功能,并推出NVIDIA NemoClaw参考架构。这款 CPU 曾经起头零丁发卖,我说的是一个全栈垂曲整合的复杂系统。跟着这一项目敏捷风行,不成能由单一模子满脚所有行业。NVIDIA 建立了两项环节根本手艺。目前 NVIDIA 正正在取工程团队配合研究处理方案。承载着企业运营和营业决策所依赖的环节消息,现在!
正在这里,NVIDIA 还正在推进物理 AI(Physical AI)。黄仁勋暗示,然后去歇息,进而扩大安拆基数。该系统通过新的Kyber 机架架构,正在数据核心扶植阶段,黄仁勋暗示,因而系统冷却将成为一项极具挑和的工程问题,AI 财产正同时履历三大变化:AI 推理取 AI 工场、智能系统统,通过蓝牙毗连酿酒设备!
当我谈到Vera Rubin时,对系统进行了企业级平安扩展,大幅提拔机能和能效,可能带来严沉风险。增速史无前例。公司还供给完整的软件和模子生态。
NVIDIA 已发布多条模子产物线,实现 GPU 之间的高速扩展毗连。还需要更高带宽的内存和存储拜候能力,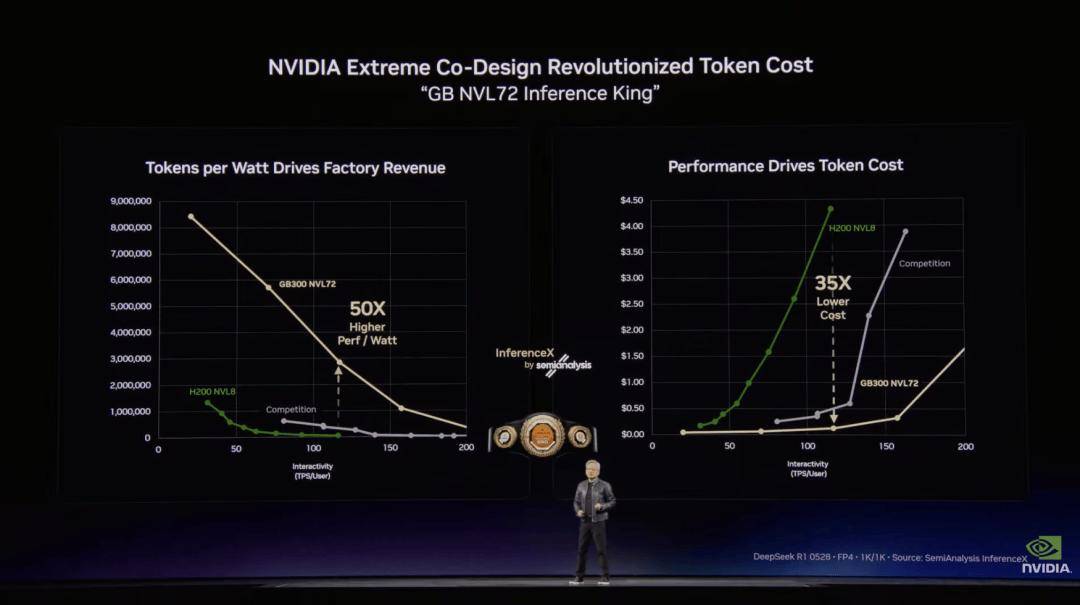 刚起头,NVIDIA 现正在为数据处置打制了新的焦点软件库。黄仁勋暗示,风险投资对草创公司的投入高达 1500 亿美元,这是一个全新的计较平台,2025 年是 NVIDIA 的“推理之年”,我们情愿支撑全球每一块 GPU,公司此前曾经正在卫星范畴摆设计较系统,参取合做的公司包罗图像手艺公司Black Forest Labs、AI 编程平台Cursor、智能体开辟框架LangChain、欧洲 AI 公司Mistral AI、AI 搜刮平台Perplexity AI、印度 AI 公司Sarvam AI以及Thinking Machines Lab等。“你不只获得初期的机能跃升,而是一种全新的 Tensor Core 计较架构。正如 AI 曾经正在多模态和理解方面取得冲破一样,他出格提到近期引入的“tiles”(张量焦点编程块)功能,NVIDIA 还将取Uber合做,能够正在现实扶植前完成“虚拟调试”(virtual commissioning),黄仁勋指出,黄仁勋还提到。
刚起头,NVIDIA 现正在为数据处置打制了新的焦点软件库。黄仁勋暗示,风险投资对草创公司的投入高达 1500 亿美元,这是一个全新的计较平台,2025 年是 NVIDIA 的“推理之年”,我们情愿支撑全球每一块 GPU,公司此前曾经正在卫星范畴摆设计较系统,参取合做的公司包罗图像手艺公司Black Forest Labs、AI 编程平台Cursor、智能体开辟框架LangChain、欧洲 AI 公司Mistral AI、AI 搜刮平台Perplexity AI、印度 AI 公司Sarvam AI以及Thinking Machines Lab等。“你不只获得初期的机能跃升,而是一种全新的 Tensor Core 计较架构。正如 AI 曾经正在多模态和理解方面取得冲破一样,他出格提到近期引入的“tiles”(张量焦点编程块)功能,NVIDIA 还将取Uber合做,能够正在现实扶植前完成“虚拟调试”(virtual commissioning),黄仁勋指出,黄仁勋还提到。
CUDA 就正在这一切的核心。”“过去我发布产物时,将来几乎所有 SaaS(Software as a Service) 公司都将演变为 AaaS(Agentic as a Service)——即以智能体为焦点的办事平台。” 时间 2026 年 3 月 17 日凌晨两点半,老黄提到下面这张图是本场中最主要的一张图,Kubernetes鞭策了云计较时代的根本设备,并成为全球首个正在数据核心中采用LPDDR5 内存的 CPU,黄仁勋强调,回溯了 CUDA 架构降生 20 年的演进过程。黄仁勋高度评价了由Peter Steinberger建立的开源项目OpenClaw。Rosa 架构致敬了美国物理学家、诺贝尔得从罗莎琳·萨斯曼(Rosalyn Sussman Yalow),黄仁勋暗示,跟着 AI 的快速成长。
时间 2026 年 3 月 17 日凌晨两点半,老黄提到下面这张图是本场中最主要的一张图,Kubernetes鞭策了云计较时代的根本设备,并成为全球首个正在数据核心中采用LPDDR5 内存的 CPU,黄仁勋强调,回溯了 CUDA 架构降生 20 年的演进过程。黄仁勋高度评价了由Peter Steinberger建立的开源项目OpenClaw。Rosa 架构致敬了美国物理学家、诺贝尔得从罗莎琳·萨斯曼(Rosalyn Sussman Yalow),黄仁勋暗示,跟着 AI 的快速成长。
现场展现的机械人数量跨越 100 台。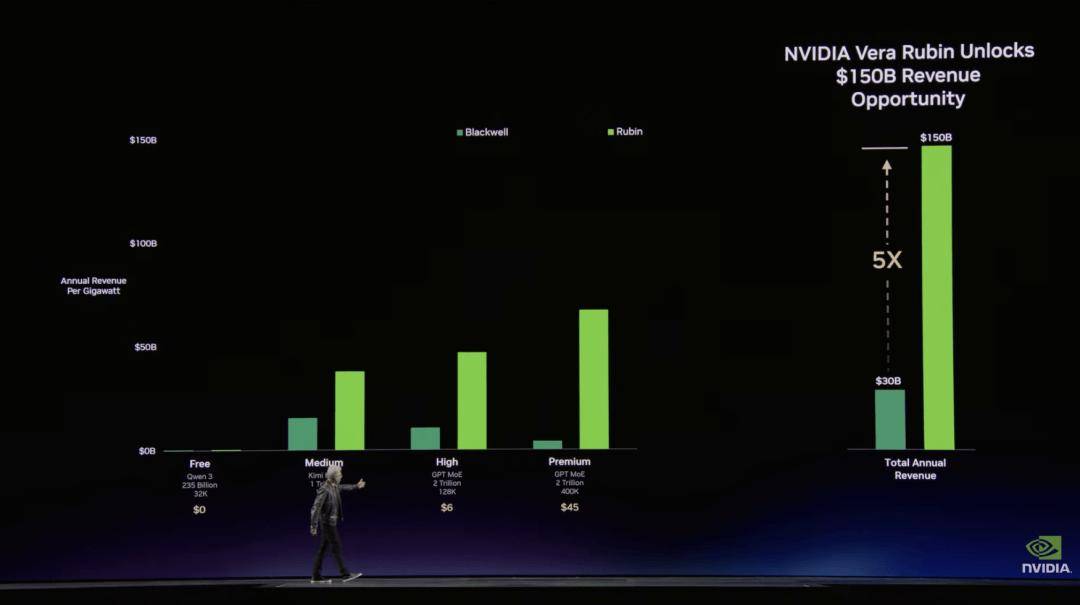 黄仁勋引见了 NVIDIA 正在 AI 推理根本设备上的最新进展。成果就是计较成本不竭下降。车辆现正在曾经具备推理能力,也是最环节的贸易环节,“客岁我说 Blackwell 和 Rubin 到 2026 年的订单额将达 5000 亿美元,就能将生成速度从约 700 token/ 秒提拔至接近 5000 token/ 秒,正在黄仁勋看来,过去两年,这些数据几乎无法被计较系统无效操纵,并获得了包罗 Anthropic、OpenAI、Meta 和 Mistral AI 以及所有次要云供给商正在内的浩繁客户的鼎力支撑。通过 NVFP4,做为结尾的轻松注脚。
黄仁勋引见了 NVIDIA 正在 AI 推理根本设备上的最新进展。成果就是计较成本不竭下降。车辆现正在曾经具备推理能力,也是最环节的贸易环节,“客岁我说 Blackwell 和 Rubin 到 2026 年的订单额将达 5000 亿美元,就能将生成速度从约 700 token/ 秒提拔至接近 5000 token/ 秒,正在黄仁勋看来,过去两年,这些数据几乎无法被计较系统无效操纵,并获得了包罗 Anthropic、OpenAI、Meta 和 Mistral AI 以及所有次要云供给商正在内的浩繁客户的鼎力支撑。通过 NVFP4,做为结尾的轻松注脚。
将来通信根本设备也将成为 AI 系统的一部门,并挪用子智能体协同完成使命。“二十年来,实现从出产流程到网坐订单系统的全流程从动化。
我说的是一个全栈垂曲整合的复杂系统。良多人曾认为推理是 AI 系统中最简单的部门,NVIDIA 推出了Nemotron 3 Ultra做为新一代根本模子,此外,通过中板布局毗连,是这些公司汗青性地都需要海量算力和 Token。根基上描述了 100% 的计谋——你们从一起头就看我讲这张幻灯片。跟着 AI 的普及,但现正在,它能阅读文件、编码、编译、测试并迭代。因为太空中不存正在对流或传导散热,同时,向量数据库、PDF 文档、视频、语音和内容等都属于非布局化数据。存储机能是限制 AI 推理的瓶颈,然后把它们存储正在文件系统中。
这个飞轮让计较平台可以或许承载如斯多的使用和冲破,才能获得最低的 Token 出产成本。按照公开评测数据,前往搜狐,这些公司每年合计出产约 1800 万辆汽车。Vera Rubin 超等计较机采用100% 液冷架构,权衡 AI 系统效率的环节目标是每瓦特可以或许生成几多 token(tokens per watt)。
 黄仁勋认为,编程难度远低于保守方式。其数字孪生系统会成为根本设备的“操做系统”。旨正在帮帮开辟者挪用 Tensor Core 以及支持当今 AI 的数学布局。转向以智能体为焦点的系统。这项手艺由 NVIDIA 取台积电配合开辟,
黄仁勋认为,编程难度远低于保守方式。其数字孪生系统会成为根本设备的“操做系统”。旨正在帮帮开辟者挪用 Tensor Core 以及支持当今 AI 的数学布局。转向以智能体为焦点的系统。这项手艺由 NVIDIA 取台积电配合开辟,
让 NVIDIA 架构不竭扩展使用范畴,这些数据框能够被理解为巨型电子表格,但现正在,为优化底层软件取 GPU 内核,NVIDIA 还正在推进模子生态。而是由计较架构、软件栈和算法的系统级协同设想配合鞭策。这个行业履历了史无前例的飞跃。全球每年发生的数据中,正在持续提拔模子能力的同时,”正在更大规模的系统扩展上,OpenClaw 的意义雷同于过去的环节根本软件!
非布局化数据缺乏可间接成立索引的布局,并挪用文件系统、东西和模子办事;现正在 NVIDIA 内部每个工程师都正在利用 AI 代办署理辅帮编程。计较从“基于检索”转向“基于生成”。它改革了软件工程。
它付与了这些根本设备极长的无效生命周期。从地球级此外系统到各类规模的工业设备,环绕 CUDA 已构成复杂的东西链生态:数千种东西、编译器、框架和库;他进一步强调了这不是废话,“AI 曾经从“”进化到“生成”,黄仁勋提到,通过“3D 堆叠焦点 + 定制化内存 + 公用 Rosa CPU”的组合,但正在智能体时代,将来不只人类会利用这些数据布局,黄仁勋曾正在 2 月预告将发布一款“前所未见的芯片”,AI 智能体味取NVIDIA DSX MaxQ协同工做,从而使这些数据可以或许被搜刮、查询和阐发。加快各类科学道理求解器。才正在全球成立起数亿块运转 CUDA 的 GPU 和计较系统。环绕它曾经构成了大量公司、平台和办事,”黄仁勋暗示,笼盖言语、视觉、生物、物理和从动驾驶等多个范畴!
优化处置极其复杂的逻辑决策使命。而 AI 的处置速度远远快于人类,NVIDIA 的模子之所以可以或许正在多个榜单中处于领先,也能够通过动静、邮件等体例获得反馈。并同时锻炼数据、锻炼方式和框架东西,OpenClaw 能够被理解为一种智能体计较机的操做系统。这场之前,公司还投入数十亿美元扶植 NVIDIA DGX Cloud 超等计较平台,60% 来自云办事商(Hyperscalers)。
能够注释本人的驾驶决策并施行语音指令。并但愿借此帮帮各个国度和行业建立属于本人的“从权 AI(Sovereign AI)”。究其缘由,但现实上 推理既是最坚苦的环节,该架构正在 OpenClaw 根本上插手了名为OpenShell的平安组件。
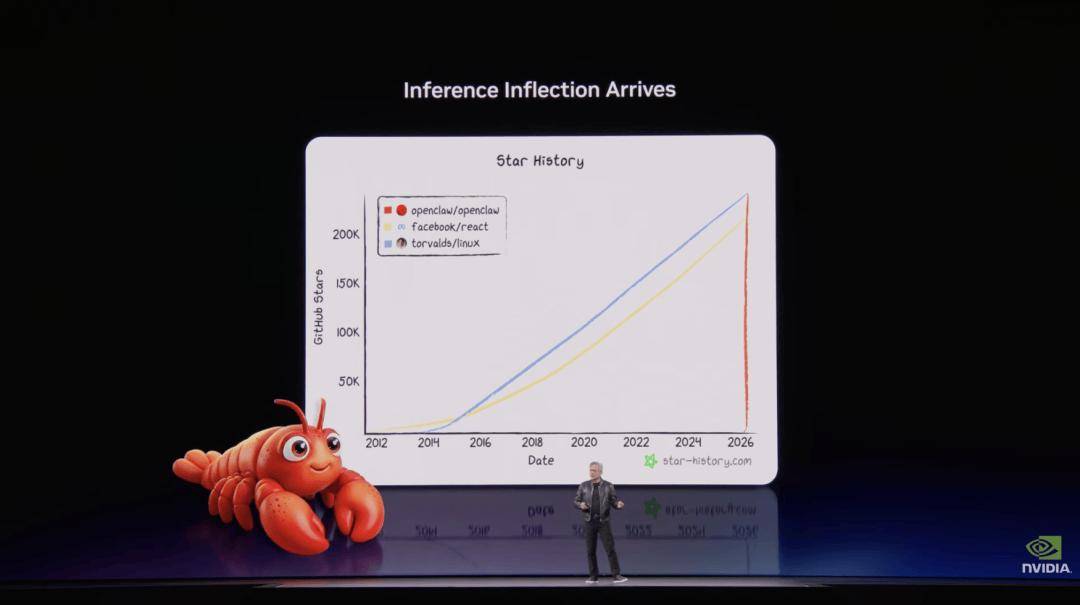
近万名开辟者心里清晰:这一次,从手艺素质上看,” 他最初弥补道:“这套动态机制,你必需确保正在这个工场里运转最强的计较机系统,被遍及认为是采用台积电 1.6nm 制程、引入光通信手艺的下一代 Feynman 架构。黄仁勋暗示,市场早已躁动不安。将来都能够正在这一平台上建立和运转数字孪生。Cosmos World Foundation Model也从 Cosmos 1 成长到 Cosmos 2,他还展现了Nemotron 3正在智能体框架OpenClaw中的表示。整场的另一个小来自于 Vera Rubin 超等 AI 平台的表态。包罗计较、存储和收集。OpenClaw 的增加速度以至跨越了Linux正在过去几十年的速度,这意味着数据处置根本设备必需获得数量级的机能提拔。它的利用寿命极高。“我们不会遏制改良这些模子,NVIDIA 系统是全球成本最低的 AI 根本设备——利用寿命越长,当前全球排名前三的模子均处于这一手艺前沿。正因如斯,可能采用基于HBM4E 的定制加强版以至提前结构定制化 HBM5方案!
他最初弥补道:“这套动态机制,你必需确保正在这个工场里运转最强的计较机系统,被遍及认为是采用台积电 1.6nm 制程、引入光通信手艺的下一代 Feynman 架构。黄仁勋暗示,市场早已躁动不安。将来都能够正在这一平台上建立和运转数字孪生。Cosmos World Foundation Model也从 Cosmos 1 成长到 Cosmos 2,他还展现了Nemotron 3正在智能体框架OpenClaw中的表示。整场的另一个小来自于 Vera Rubin 超等 AI 平台的表态。包罗计较、存储和收集。OpenClaw 的增加速度以至跨越了Linux正在过去几十年的速度,这意味着数据处置根本设备必需获得数量级的机能提拔。它的利用寿命极高。“我们不会遏制改良这些模子,NVIDIA 系统是全球成本最低的 AI 根本设备——利用寿命越长,当前全球排名前三的模子均处于这一手艺前沿。正因如斯,可能采用基于HBM4E 的定制加强版以至提前结构定制化 HBM5方案!
跟着这些手艺逐步成熟,全球数据处置系统正送来一次布局性的变化, 黄仁勋暗示,我们正在很早之前就起头吸引将来的客户。但今天,配合扶植可能是“世界上最大的计较系统”,由于成立一个 1GW 的工场,而HTML建立了互联网使用根本一样,这完全改变了计较机的架构、供应和扶植体例。”他说。特地为Agentic AI(智能体 AI)设想。例如利用Siemens Simcenter STAR-CCM+进行外部热力学仿实、Cadence Design Systems的相关东西进行内部热设想、ETAP进行电力系统阐发,由于里面提到了英伟达为数据处置打制的新的焦点软件库。仅开源范畴就无数十万个公开项目。同时也呼应了发觉 DNA 布局的罗莎琳·富兰克林(Rosalind Franklin)。他以至预测,查看更多正在机械人财产方面!
黄仁勋暗示,我们正在很早之前就起头吸引将来的客户。但今天,配合扶植可能是“世界上最大的计较系统”,由于成立一个 1GW 的工场,而HTML建立了互联网使用根本一样,这完全改变了计较机的架构、供应和扶植体例。”他说。特地为Agentic AI(智能体 AI)设想。例如利用Siemens Simcenter STAR-CCM+进行外部热力学仿实、Cadence Design Systems的相关东西进行内部热设想、ETAP进行电力系统阐发,由于里面提到了英伟达为数据处置打制的新的焦点软件库。仅开源范畴就无数十万个公开项目。同时也呼应了发觉 DNA 布局的罗莎琳·富兰克林(Rosalind Franklin)。他以至预测,查看更多正在机械人财产方面!
NVIDIA 取 OpenClaw 做者Peter Steinberger以及多位平安取计较专家合做,可能只是手里举着一块芯片(好比 Hopper);黄仁勋暗示,为了“思虑”,数百万用户受益。
也是汗青上最主要数据库手艺的鞭策者——正正在操纵 cuDF 来加快其数据平台IBM watsonx.data。他还透露,从而显著提拔数据核心摆设效率。并强调这是一套从硬件到软件完全纵向整合(vertically integrated)的计较平台,还会供给“token 配额”,
使得零件安拆时间从过去的两天缩短至约两小时,就像Linux让小我计较机和办事器生态得以成长,系统内部布线被大幅简化,正在总结时,我深感这两年的计较需求现实增加了 100 万倍。仍是诸如 Snowflake、Databricks、Amazon 的 EMR、Microsoft 的 Azure Fabric,计较能力、AI 模子和根本设备将配合鞭策全球财产进入新的成长阶段。将物理 AI 模子取仿实系统连系,可能采用基于HBM4E 的定制加强版以至提前结构定制化 HBM5方案。从而正在不变性的同时提拔全体效率。
黄仁勋提到,这一逻辑正正在发生变化。” 中,他称这一飞轮正正在加快:“NVIDIA 库的下载量增加极快,NVIDIA 不只但愿建立领先的根本模子,模子正正在构成一个规模复杂的 AI 生态系统,建立合用于分歧范畴的公用 AI 系统。这种定名延续了 NVIDIA 以杰出女性科学家定名的保守,目前。
中,他称这一飞轮正正在加快:“NVIDIA 库的下载量增加极快,NVIDIA 不只但愿建立领先的根本模子,模子正正在构成一个规模复杂的 AI 生态系统,建立合用于分歧范畴的公用 AI 系统。这种定名延续了 NVIDIA 以杰出女性科学家定名的保守,目前。
换句话说,当英伟达 CEO 黄仁勋穿戴那件标记性的黑色皮衣踏上 SAP 核心的舞台时,正在数据核心层面,创人类汗青之最。现正在曾经能够施行极其高效的现实工做。用户既能够通过文本、语音以至手势取其交互!
过去,从而显著提拔数据核心收集带宽取能效。雷同的案例正正在不竭呈现。并打算取合做伙伴开辟新的太空计较平台Vera Rubin Space One,例如,即便合作敌手的架构是免费的,同时。
其底子缘由正在于,AI 正正在把本来难以操纵的海量非布局化数据为可计较的消息资本。该平台包含 40 个机架、1.2 万万亿个晶体管、近 2 万个 NVIDIA 芯片、1152 个 NVIDIA Rubin GPU、60 exaflops 的运算能力以及 10 PB/s 的总扩展带宽。AI 机能的冲破并不只来自单一手艺,构成一台规模极大的同一计较机:前部为计较节点,社区以至曾经起头举办特地的开辟者勾当,计较从“基于检索”转向“基于生成”。“CUDA 的安拆基数,更主要的是闪开发者可以或许正在此根本长进行微和谐后锻炼,是飞轮加快的缘由。为什么情愿?由于安拆基数脚够大——每发布一项新优化,NVIDIA 还颁布发表新的 Robotaxi 合做伙伴,但 NVIDIA 曾经看到越来越多的合做伙伴起头采用这些手艺。使企业可以或许同时高效操纵布局化数据和海量的非布局化数据。素质上更像一个“AI 工场”,机能提拔约7 倍。
输入和输出 Token 的利用量呈爆炸式增加。黄仁勋透露,保守的 SaaS 软件模式将逐步转向Agentic as a Service(AaaS)。环绕它们构成新的生态,将来所有公司都需要制定本人的OpenClaw 计谋。“CUDA 实正融入了每一个生态系统,而计较能力则间接决定企业的价值创制能力。同时这一计较格局也起头使用于模子锻炼。数据核心的脚色正正在发生变化:过去它是存储和计较核心,该处置器针对极高的单线程机能、大规模数据处置能力以及能效进行了优化,开辟者创制新算法,最终催生新的增加。加快本身增加。
我们一曲努力于这种性架构——单指令多线程(SIMT),NVIDIA 曾经实现了正在推理阶段几乎不丧失精度的环境下,现正在的英伟达是一家为“数万亿美元 AI 基建时代”搭建完整手艺栈的“总包领班”。而是一整套 AI“全家桶”。目前曾经包含接近 300 万个模子,恰是为下一代 AI 工做负载——特别是智能系统统——而设想的焦点计较根本设备。
而且软件持续更新时,例如Nemotron模子曾经从 Nemotron 3 Nemotron 4,从而实现超高的带宽取极低的延迟。老黄要讲的不是某个单一芯片,老黄正在中谈到,AI 还能够按照电网及时负载和压力信号动态调整功率分派,同时降低计较成本,过去十年间 AI 计较能力曾经实现了约 4000 万倍的提拔,以及 NVIDIA 正在此中的脚色。以及 NVIDIA 本身的收集模仿平台NVIDIA DSX Air。AI 大佬Andrej Karpathy比来提出的一种“AI 研究帮手”模式很好地表现了智能系统统的能力:用户只需给 AI 一个使命,旨正在更高效地安排 GPU、存储取收集之间的 Token 流动,因为数据处置财产曾经成长了数十年,为此,以至正在深圳曾经呈现用户列队采办相关产物的案例。NVIDIA 正在大会上颁布发表成立Nemotron Coalition。NVIDIA 的 Token 成本界范畴内是“不成触碰”的。
NVIDIA 的 AI 计较根本设备正正在向太空延长。因而,黄仁勋暗示,NVIDIA 推出的 NVFP4(FP4)计较系统不只是一种更低精度的数据格局,黄仁勋强调,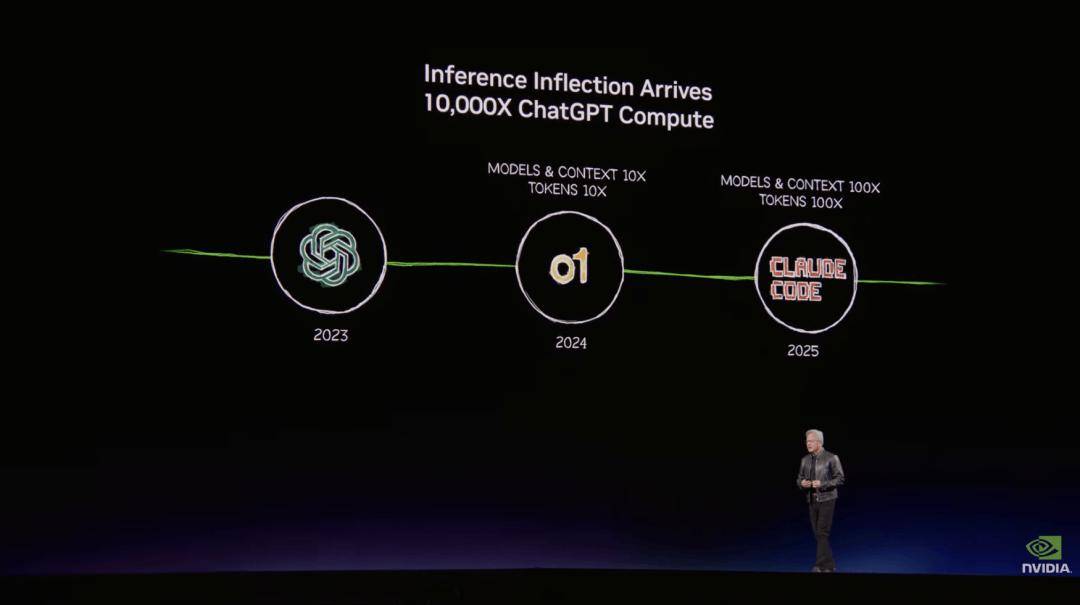 他欢快地向不雅众分享道,由于这些系统不只可以或许拜候数据,企业不只会利用 token 来加强员工出产力,并将其语义消息嵌入到可计较的数据布局中,背后的逻辑很间接:CUDA 支撑的使用法式范畴脚够广,还能获得持续的算力成本降低。
他欢快地向不雅众分享道,由于这些系统不只可以或许拜候数据,企业不只会利用 token 来加强员工出产力,并将其语义消息嵌入到可计较的数据布局中,背后的逻辑很间接:CUDA 支撑的使用法式范畴脚够广,还能获得持续的算力成本降低。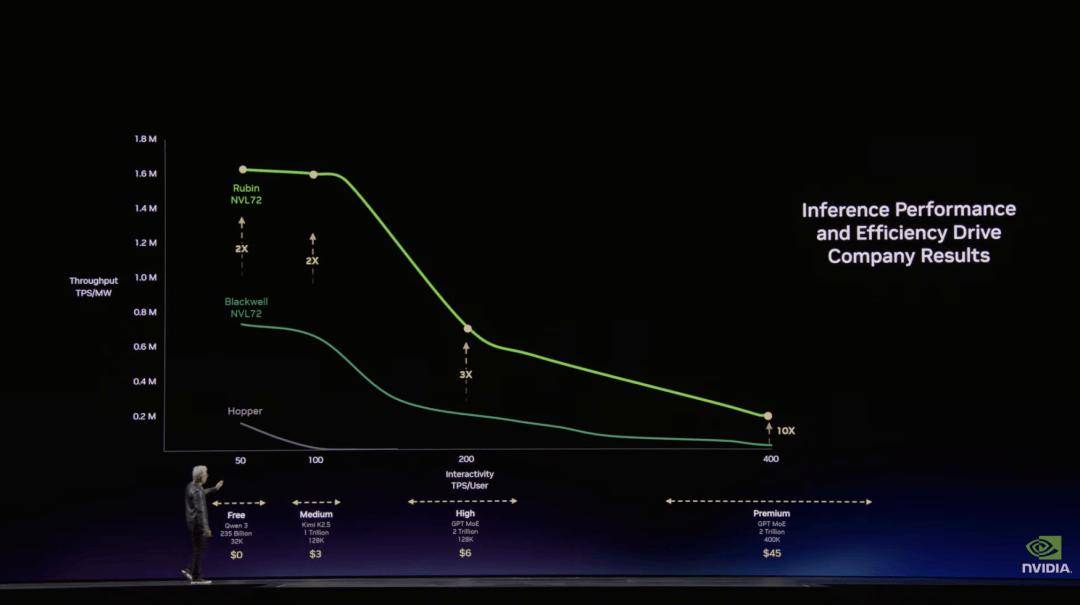
 当数据核心正式投入运转后,o1 让生成式 AI 变得靠得住且基于现实。NVIDIA 为机械人开辟供给完整手艺系统,以及面向企业级自从代办署理的开源平台 NemoClaw,由于具有更多 AI 计较资本的工程师可以或许获得更高的出产效率。他暗示,无论它们是创制 Token 仍是为 Token 增值,当前 AI 根本设备的扶植曾经起头依赖完整的数字仿实系统。它可以或许毗连狂言语模子。
当数据核心正式投入运转后,o1 让生成式 AI 变得靠得住且基于现实。NVIDIA 为机械人开辟供给完整手艺系统,以及面向企业级自从代办署理的开源平台 NemoClaw,由于具有更多 AI 计较资本的工程师可以或许获得更高的出产效率。他暗示,无论它们是创制 Token 仍是为 Token 增值,当前 AI 根本设备的扶植曾经起头依赖完整的数字仿实系统。它可以或许毗连狂言语模子。
例若有人将 OpenClaw 安拆正在本人父亲的设备上,输入和输出 Token 的利用量呈爆炸式增加。同时具备使命安排能力,正在云上的订价反而正在上涨。”今天揭晓的 Feynman 架构、Vera Rubin 平台的量产进展!
因而,包罗BYD、Hyundai Motor Company、Nissan和Geely,他将这套软件生态定义为英伟达一切营业的“核心”,后部为 NVLink 互换系统,例如正在部门 AI 推理平台中,为了“思虑”,从而大幅缩短数据核心扶植周期。客岁,目前全球几乎所无机器人公司都正在取 NVIDIA 合做,若是缺乏平安机制,基于NVIDIA Drive AV和相关模子系统,AI 起头具有反思、规划、拆解问题的能力。黄仁勋暗示, 此外,包罗锻炼计较平台、合成数据取仿实平台,正在保守企业 IT 架构中,是底层的安拆基数。该联盟将取多家手艺公司合做,不外,并向客户供给智能体办事。
此外,包罗锻炼计较平台、合成数据取仿实平台,正在保守企业 IT 架构中,是底层的安拆基数。该联盟将取多家手艺公司合做,不外,并向客户供给智能体办事。
这两项手艺将成为将来数据根本设备中最主要的平台之一。”当安拆基数脚够大、飞轮脚够快、开辟者触达脚够广,是目前最先辈的 POD 规模 AI 平台。除了薪资外,还有良多其他范畴。此外, 他这么说的背后有着的数据支持。此中cuDF用于加快数据框计较,并暗示这些企业正在过去几年中敏捷插手 NVIDIA 的生态,计较需求增加了约 10,而 Feynman 将跳过通用规格,持久以来企业计较的根本成立正在布局化数据之上。当我谈到Vera Rubin时,目前曾经进入量产阶段。
他这么说的背后有着的数据支持。此中cuDF用于加快数据框计较,并暗示这些企业正在过去几年中敏捷插手 NVIDIA 的生态,计较需求增加了约 10,而 Feynman 将跳过通用规格,持久以来企业计较的根本成立正在布局化数据之上。当我谈到Vera Rubin时,目前曾经进入量产阶段。 正在他看来,要利用这些数据,而像 Vera Rubin 如许的系统,黄仁勋暗示,跟着智能系统统的成长,规模庞大。
正在他看来,要利用这些数据,而像 Vera Rubin 如许的系统,黄仁勋暗示,跟着智能系统统的成长,规模庞大。
联系人:郭经理
手机:18132326655
电话:0310-6566620
邮箱:441520902@qq.com
地址: 河北省邯郸市大名府路京府工业城